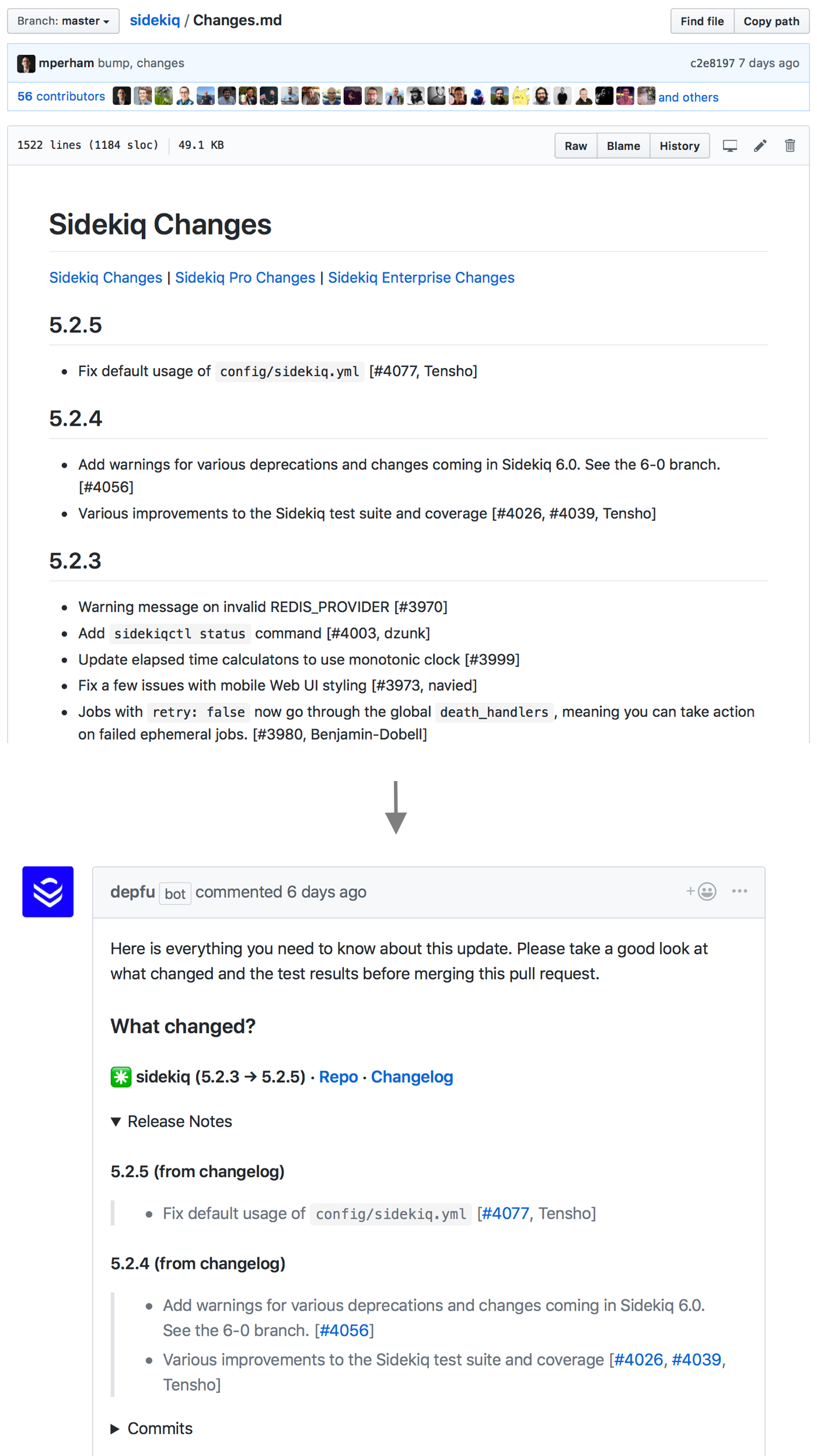
Now with more changelog contents
 Jan Krutisch, Co-Founder at Depfu
Jan Krutisch, Co-Founder at DepfuIn our pull requests, we try to cram in as much useful information about the dependency update as possible. One obviously important bit is “What did actually change?” Up until now, we’ve presented that in the following order:
- Link to the changelog
- Release information from GitHub releases
- Commit titles
The most useful part here has always been the release text - As it’s the actual “changelog entry” right within the pull request. The link to the changelog was always a bit of a letdown - We know where you’ll find the information, but you’ll have to go to it yourself and read through the whole thing on your own.
From now on, we’re displaying information directly from the changelog for the majority of packages. This saves Depfu users another click (and context change) and also, since we’re only displaying the changelog parts relevant to the update, this should be easier to “parse” for people (see what I did there?). This article talks a little about what went into this.
The challenges
The main problem, with changelogs, of course, is that everyone uses a different format for writing those. This makes writing a simple generic parser somewhat challenging (others would say: impossible).
One of the best decisions we made when writing our own parser (for prior art, look here and here) is to not parse each and every plain text format but instead render the changelog to HTML (using, for most changelogs, the HTML endpoint of GitHub’s file API) and use the HTML structure to try to extract the needed information. This has two benefits. First of all, we don’t have to deal with the gazillion of different text formats people use to write changelogs. GitHub is pretty good at turning these into relatively uniform HTML using their Markup library. Secondly, we can use Nokogiri, Ruby’s awesome XML and HTML parser. If we were to analyze the textual input formats, we probably would have to write (or find) parsers for the top most used input formats ourselves and then also deal with things like different indentation methods and levels etc.
It wasn’t as bad as we thought
Surprisingly, currently the parser is still below 200 lines of relatively structured ruby code (which uses frightening amounts of XPath expressions) and probably unsurprisingly, it is a proper 80% solution. Our reasoning here is that even if we are only able to extract changelog info for a subset of all packages our users use, this still makes our service better.
We approached this by looking at our own stats of the most used packages, and making sure their changelogs would parse properly. We built a bit of tooling around it that allows us to review the parsed changelogs within our admin panel. And then it was a matter of detecting various common variants and parsing them correctly.
There be dragons mistakes
In contrast to the information we extract from GitHub release notes, this is not a fail safe thing, though. Our parser might choke on something, detect versions blocks incorrectly (especially easy if people mark up their changelog in strange ways) and then even display the wrong info for the wrong version. We try to prevent this by bailing out as soon as the parser detects any issues, but we’ve seen people use incredibly weird formats and as with every parser, there are probably at least a handful of ways how you can format a changelog that looks okay to a human but completely throws off our poor parsing robots.
What you can do
Because of that, if a PR contains info extracted from a changelog, we’ll add a link that will directly take you to a feedback form, so that you can help us make this better.
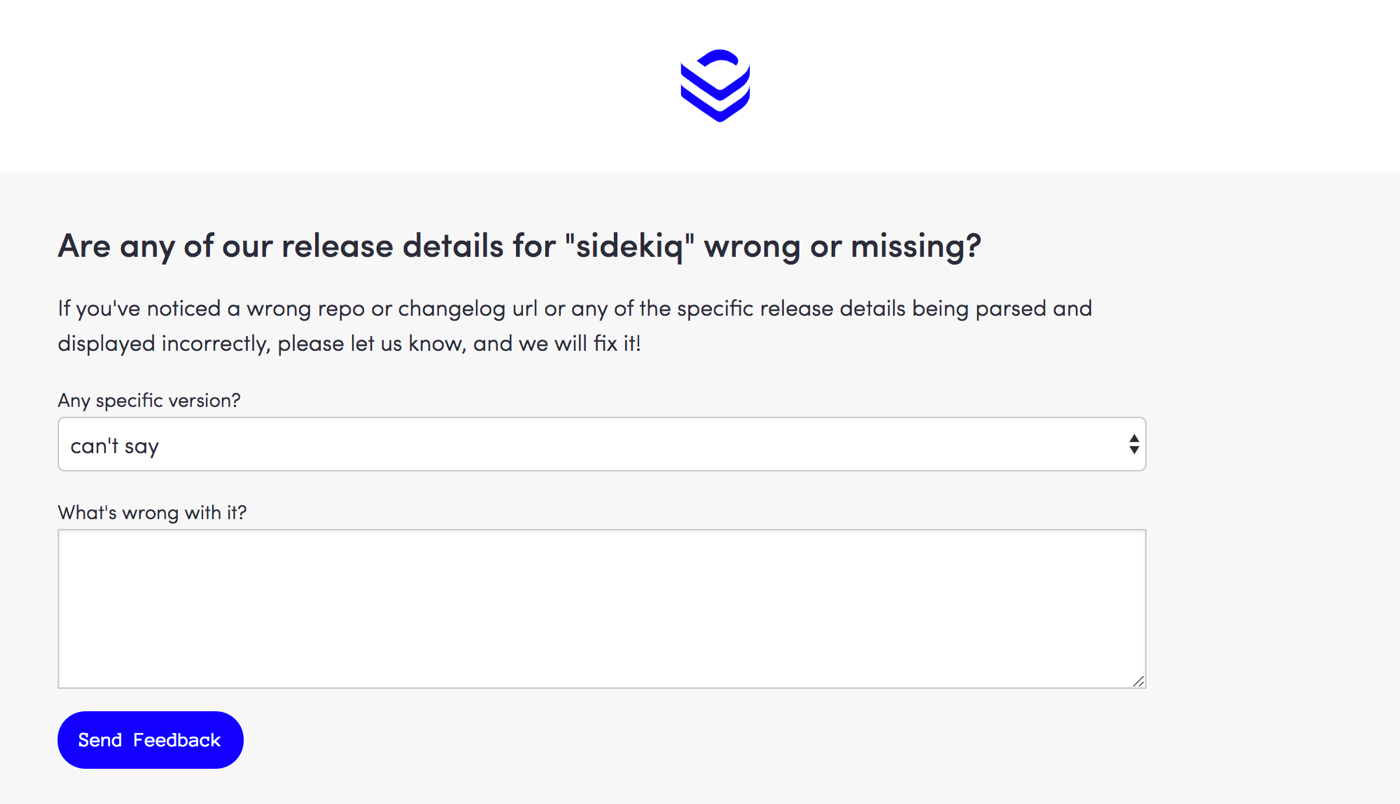
Also, if you are an open source package maintainer and you want us to be able to parse your changelog, here’s a couple of things you can do:
- Use a standard format like Markdown as this gives the best results for conversion to HTML. It is simply GitHub’s gold standard for text formatting and thus has the best support.
- Have your version numbers (formatted as semver compliant version numbers) in headlines. This is how we detect version blocks in the HTML. You can use release code names as long as the version is in the headline as well.
- Try to prevent to use overly complicated markup constructs like tables. Headlines and nested lists should get you all the way.
Basically, perhaps unsurprisingly, if you follow our advice for writing a good changelog, you should be fine 😇.
A parser for changelogs is one of those projects that is never really finished. The following months and feedback from our users will show us where we can improve the parser - Additionally, we think about also giving feedback to open source authors on typical formatting errors that break automatic parses and of course we’ll continue to raise awareness of the importance of changelogs that are easy to read and properly formatted/ well formed.